
Tu viens de passer deux heures à copier des prix et des emails dans un Excel. Tu as mal aux yeux, tu as fait 30 lignes, et il t’en reste 500.
Il existe une extension Chrome gratuite capable de faire ce boulot pendant que tu te sers un café. Sans coder. Sans développeur. Sans abonnement.
Ce guide dérouле exactement comment ça marche — avec la même extension que Cyril Bentz utilise dans plus de 70% de ses besoins data depuis +5 ans.
C’est mathématique. Pas magique.
Table des matières
- Scraping vs crawling : la différence en une phrase
- Étape 1 — Installer Web Scraper en 10 minutes
- Étape 2 — Comprendre la structure d’une page (sans coder)
- Étape 3 — Créer un sitemap et définir tes données
- Étape 4 — Scraper une page et exporter en Excel
- Étape 5 — Crawler un site entier : 2 méthodes
- Étape 6 — Les scripts prêts pour Amazon
- Étape 7 — Exploiter les données avec RECHERCHEV
- Questions fréquentes
Scraping vs crawling : la différence en une phrase
Le web scraping, c’est extraire des données d’une seule page web — une page de résultats Amazon, un annuaire d’une seule page, un tableau de données. Tu décris ce que tu veux récupérer (titres, prix, emails, ASIN…), le robot aspire tout et t’exporte un fichier Excel.
Le crawling, c’est le même mécanisme appliqué à plusieurs pages d’un même site. Tu expliques au robot comment naviguer de page en page. Il fait tourner en automatique.
En pratique pour un vendeur Amazon : le scraping sert à analyser une page de résultats, le crawling à aspirer un catalogue concurrent sur 12 pages ou les 7 premières pages d’un mot-clé. Pour un prospecteur B2B : le scraping aspire un annuaire d’une page, le crawling parcourt un annuaire multi-pages sans intervention manuelle.
La compétence n’a pas de valeur parce qu’elle scrape. Elle a de la valeur parce qu’elle remplace des heures de copier-coller par une donnée exploitable directement dans ton business.
L’outil pour les deux : Web Scraper, une extension Chrome disponible gratuitement sur le Chrome Web Store.
Étape 1 — Installer Web Scraper en 10 minutes
Web Scraper fonctionne uniquement sur les navigateurs basés sur Chromium : Chrome et Brave.
Pour l’installer :
- Cherche “Web Scraper Free Web Scraping” sur le Chrome Web Store
- Clique sur “Installer l’extension”
- Ouvre les outils de développement :
Menu (3 points) → Plus d'outils → Outils de développement - Tu verras un onglet “Web Scraper” dans la barre du bas
C’est tout. 10 minutes installation comprise.
Avant de scraper quoi que ce soit, un réflexe qui te fera gagner du temps : les bases de données publiques (data.gouv.fr et autres sources Open Data) mettent à disposition des milliers de données déjà structurées, téléchargeables en Excel. Prospection B2B, données géographiques, études de marché — vérifie d’abord si les données existent en Open Data. C’est parfois beaucoup plus rapide que de scraper.
Étape 2 — Comprendre la structure d’une page (sans coder)
Pour scraper, tu n’as pas besoin d’écrire du code. Mais tu dois comprendre une chose : chaque page web est une hiérarchie de blocs qui contiennent des sous-blocs.
Sur une page de résultats Amazon, tu as un bloc “annonce” qui contient un “titre”, un “prix”, des “avis”. Sur un annuaire, tu as un bloc “contact” qui contient un “nom”, un “email”, un “téléphone”. C’est exactement cette logique que Web Scraper reproduit.
Pour visualiser ça :
- Va sur n’importe quelle page
- Clique droit sur un élément → Inspecter
- Le panneau qui s’ouvre te montre le code HTML qui décrit cette zone — tu vois les blocs imbriqués
L’astuce clé : sur Amazon, les résultats organiques et les résultats sponsorisés ont des structures HTML légèrement différentes. C’est ce qui te permettra de n’aspirer que l’un ou l’autre selon ce que tu cherches.
Étape 3 — Créer un sitemap et définir tes données
Dans Web Scraper, un sitemap est simplement la configuration de ce que tu veux récupérer. Un sitemap = une mission de scraping. Une fois créé, c’est un actif réutilisable : tu changes l’URL cible, tu relances.
Pour créer un sitemap :
- Dans l’onglet Web Scraper → “Create new sitemap” → “Create sitemap”
- Donne-lui un nom (ex :
audit-concurrent-belote) - Colle l’URL de la page à scraper — en gardant uniquement la partie utile (sans les paramètres de session ou de tracking)
Pour définir les données : la logique parent/enfant
C’est le cœur de la méthode. Pense à des poupées russes : tu définis d’abord le “conteneur” (le bloc qui se répète), puis les données à l’intérieur.
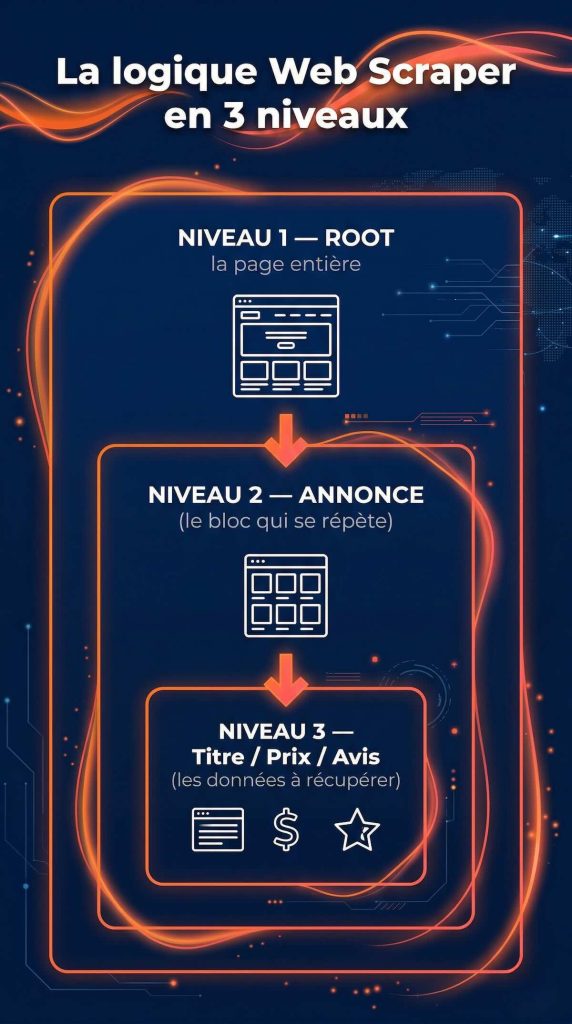
Exemple pour aspirer des annonces Amazon :
- Ajoute un élément
annonce— type : Element — mode : Multiple (car il y en a plusieurs) - Sélectionne visuellement une première annonce organique (pas “Sponsorisé”) → appuie sur
Ppour remonter au bloc parent → applique à tous les éléments similaires →Done Selecting→Save - Descends dans
annonce(clique dessus pour descendre d’un niveau) → ajoute les enfants :
titre— type : Texteprix— type : Textemoyenne_avis— type : Textenombre_avis— type : Texte
Le Selector Graph te montre la hiérarchie : root → annonce → titre / prix / avis. Clique sur “Data Preview” pour vérifier que les données remontent correctement avant de lancer.
Étape 4 — Scraper une page et exporter en Excel
Une fois ta structure définie :
- Dans l’onglet Web Scraper → sélectionne ton sitemap → Scrape
- Une fenêtre s’ouvre, le robot aspire les données en direct
- Quand c’est terminé :
Sitemaps → Export Data → CSV ou Excel
Tu récupères un fichier structuré avec une ligne par annonce et une colonne par donnée.
Ce que ça donne en pratique (ordres de grandeur) :
- Un annuaire d’une seule page avec 50 contacts → aspiré en quelques secondes
- Les premières annonces Amazon sur un mot-clé → récupérées en moins d’une minute
- Un catalogue concurrent (titres, prix, avis, ASIN) sur une page → exporté en 2 minutes
Pour une seule page, c’est tout. Pour un site multi-pages, passe à l’étape suivante.
Étape 5 — Crawler un site entier : 2 méthodes
Méthode 1 : Pagination par lien (bouton “Suivant”)
Cette méthode fonctionne quand le site a un bouton “Page suivante” en bas de page. C’est le cas de la plupart des annuaires.
Tu crées un élément suivant de type Link au même niveau que annonce. Tu sélectionnes le bouton “Suivant”. Ensuite, tu indiques dans les paramètres de l’élément annonce que son parent est à la fois root et suivant.
Ce que ça dit au robot : “Sur cette page, récupère les annonces. Ensuite, clique sur Suivant. Sur la page suivante, récupère encore les annonces. Et repère encore le bouton Suivant.”
La boucle tourne jusqu’à ce qu’il n’y ait plus de bouton Suivant. Résultat : un annuaire de 12 pages aspiré en une seule opération, sans intervention manuelle.
Méthode 2 : Pagination par URL formatée
Sur certains sites (dont Amazon), la pagination est gérée dans l’URL. Exemple : amazon.fr/s?k=tapis+jeu+de+cartes&page=2
Dans ce cas, tu modifies directement l’URL dans le sitemap avec un paramètre variable :
amazon.fr/s?k=tapis+jeu+de+cartes&page=[1-7]Ce [1-7] dit au robot de faire tourner la valeur de 1 à 7. Il scrape la page 1, puis 2, puis jusqu’à 7. En une seule opération.
Variantes utiles :
[1-20]→ pages 1 à 20[20-40]→ pages 20 à 40 (scraper par tranches)[1-20:2]→ pages 1, 3, 5… 19 (une page sur deux)
⚠️ Point d’attention : certains gros sites peuvent détecter un scraping trop intensif. Reste dans un usage raisonnable — 3 à 7 pages pour un audit Amazon, pas 50. Utilise les intervalles entre requêtes (paramètre de délai dans Web Scraper). La formation couvre ce point en détail.
Étape 6 — Les scripts prêts pour Amazon
C’est là que la méthode prend une dimension différente des tutos génériques. Plutôt que de reconstruire chaque sitemap depuis zéro, tu importes un script JSON en 1 clic — les mêmes scripts que Cyril utilise pour piloter ses analyses Amazon.
3 scripts inclus dans la formation :
🎯 Script 1 — Termes de recherche d’une niche (Explorateur d’Opportunité Produit)
Tu récupères les termes de recherche qui génèrent ~80% des clics d’une niche Amazon : terme, volume de recherche, croissance trimestrielle, croissance annuelle, part de clic, taux de conversion. Ce sont les données natives d’Amazon — pas des estimations statistiques calculées par un outil tiers. C’est là que la différence est nette : Helium 10 modélise, toi tu lis directement la source.
🎯 Script 2 — Audit de positionnement (première page)
Tu scrapes la première page organique d’un mot-clé et récupères les ASIN présents. En croisant avec ton catalogue via RECHERCHEV, tu sais en 10 secondes sur quels mots-clés tu es visible et où tu as des trous.
🎯 Script 3 — Catalogue concurrent
Tu aspires le catalogue complet d’un concurrent : titres, prix, avis, ASIN, images. En quelques minutes, tu as une vue exhaustive de ce qu’il propose.
Pour utiliser un script :
- Copie le JSON du script (disponible dans les ressources de la formation)
- Dans Web Scraper :
Import Sitemap→ colle le JSON → donne-lui un nom - Va dans
Edit Metadata→ change l’URL cible (ton mot-clé, ta niche) - Lance le scrape
Étape 7 — Exploiter les données avec RECHERCHEV
Récupérer des données sans les exploiter, c’est du stockage. Voilà comment les transformer en décisions.
Cas concret : audit de positionnement Amazon
Tu veux savoir sur quels mots-clés tes ASIN apparaissent en première page. Voilà la mécanique :
- Tu as ta liste d’ASIN dans un Google Sheet (colonne A)
- Tu aspires la première page du mot-clé cible → tu récupères les ASIN présents en organique
- Tu colles les données aspirées dans le même fichier (autre onglet)
- Tu crées une colonne “Présent” avec une
RECHERCHEV:
=RECHERCHEV(A2, $D:$E, 2, 0)- Tu ajoutes une mise en forme conditionnelle : vert si ASIN présent, rouge si absent
Résultat : un tableau de bord visuel qui te montre en 10 secondes où tu es visible et où tu as des trous à combler. Ce genre d’audit prenait 45 minutes à faire à la main. Avec cette méthode : 10 minutes, données réelles directement extraites d’Amazon.
Questions fréquentes
Est-ce que le web scraping est légal ?
En B2B (données de professionnels), c’est la règle de l’opt-out : tu as le droit d’envoyer des emails à des professionnels sans consentement préalable, à condition de leur donner la possibilité de se désabonner. En B2C (particuliers), c’est l’opt-in : il faut un consentement préalable. La formation inclut un point RGPD complet qui précise exactement ce que tu as le droit de scraper et comment l’utiliser sans risque.
Est-ce que ça marche sur Amazon ? Ils ne bloquent pas ?
Ça fonctionne dans un usage raisonnable. Amazon peut détecter un comportement anormal si le volume est trop élevé ou la cadence trop rapide. La formation couvre ce point : comment paramétrer un délai entre les requêtes, comment limiter le nombre de pages par opération, et comment gérer les cas de blocage. Pour 3 à 7 pages d’audit, la méthode est documentée et opérationnelle.
J’utilise déjà n8n / Make. En quoi ça m’aide ?
Le scraping est la brique d’entrée de tes automations. Tu récupères les données brutes depuis le web, tu les exportes en CSV, tu les injectes dans tes workflows. Avant, tu faisais ça à la main ou tu payais une API. Avec Web Scraper, c’est gratuit et tu contrôles exactement ce que tu récupères. C’est la pièce qui manquait à ta stack.
Conclusion
Le web scraping sans code, c’est une compétence de 2 heures. Une fois maîtrisée, tu changes de regard sur tous les sites web : tu ne vois plus des pages, tu vois des bases de données à portée de clic.
Les cas d’usage se multiplient rapidement : un annuaire de prospects, un audit de positionnement Amazon, un catalogue concurrent, des données de marché. À chaque fois, la même logique — sitemap, sélection des éléments, export — et 5 minutes au lieu de 3 heures.
L’outil est gratuit. Les scripts sont prêts. La méthode est là.
👉 Si tu copies encore tes données à la main, tu n’as pas un problème de motivation. Tu as un problème de méthode. La formation Scrapper & Crawler les Données du Web est là pour corriger ça — 99€, accès immédiat, garantie 30 jours.



