Tu regardes une vidéo de 40 minutes sur une stratégie business. Tu prends deux ou trois notes mentales. Une semaine plus tard, tu as besoin du chiffre précis qu’il avait cité à la 23e minute. Tu fouilles ton historique YouTube. Rien. Tu interroges ChatGPT. Il te sort des généralités qui auraient pu venir de n’importe où.
Le problème n’est pas YouTube. Le problème, c’est l’absence de système entre ce que tu consommes et ce que tu peux réutiliser. Une base de connaissances YouTube résout exactement ça : elle aspire, transcrit, structure et vectorise tes chaînes cibles pour que tu puisses les interroger en 30 secondes — comme un assistant branché sur ta bibliothèque vidéo.
👉 Cortex Youtube — construire ton système en un week-end, workflows inclus
Table des matières
- Qu’est-ce qu’une base de connaissances YouTube avec n8n et Pinecone ?
- Pourquoi ChatGPT seul ne remplace pas ce système
- Les 4 étapes pour construire le pipeline
- Ce que ça coûte réellement de faire tourner le système
- Ce que tu peux faire avec ta base une fois opérationnelle
- Questions fréquentes
Qu’est-ce qu’une base de connaissances YouTube avec n8n et Pinecone ?
Une base de connaissances YouTube, c’est un pipeline automatisé en 6 étapes : surveiller des chaînes → récupérer les métadonnées → transcrire → découper en blocs → vectoriser dans Pinecone → interroger par chat. Le tout orchestré par n8n, sans écrire une ligne de code.
Ça ressemble à quoi concrètement ? Tu poses une question à ton chatbot. Il fouille en 2 secondes dans l’intégralité des vidéos que tu as indexées — 50, 100, 200+ — et te retourne une réponse avec les sources exactes : titre de la vidéo, chaîne, date de publication.
Ce n’est pas un résumé généré à l’aveugle. C’est une réponse construite depuis tes données à toi, validées par toi. Aucune invention possible si le prompt système est correctement cadré (“si la réponse n’est pas dans les extraits fournis, dis que tu ne sais pas”).
Les 4 briques du système :
- YouTube — la source de données brutes
- Airtable — la base de données centrale (jusqu’à 1 000 vidéos en gratuit)
- Pinecone — la mémoire vectorielle de l’IA (200+ vidéos stockées gratuitement)
- n8n — le moteur d’automatisation qui fait tourner tout le pipeline
Pourquoi ChatGPT seul ne remplace pas ce système
ChatGPT ne sait pas ce que tu as regardé sur YouTube il y a trois semaines. C’est mathématique. Sa connaissance s’arrête à sa date d’entraînement, et il n’a aucun accès à ta veille personnelle.
Résultat : si tu lui poses une question sur une stratégie vue dans une vidéo de ton secteur, il te répond avec du contenu générique. Des généralités polies. Ce que Cyril appelle “les hallucinations polies” — rien de faux en apparence, rien d’utile non plus.
L’autre différence, c’est la souveraineté de tes données. Si YouTube supprime une vidéo demain, ta transcription reste chez toi. Elle est dans ta base Airtable, vectorisée dans ton Pinecone. Tu possèdes l’information. Tu ne dépends plus de la disponibilité de la vidéo.
Un RAG (Retrieval-Augmented Generation) corrige les deux problèmes : il branché l’IA sur tes données propres, et les données restent les tiennes.
Les 4 étapes pour construire le pipeline
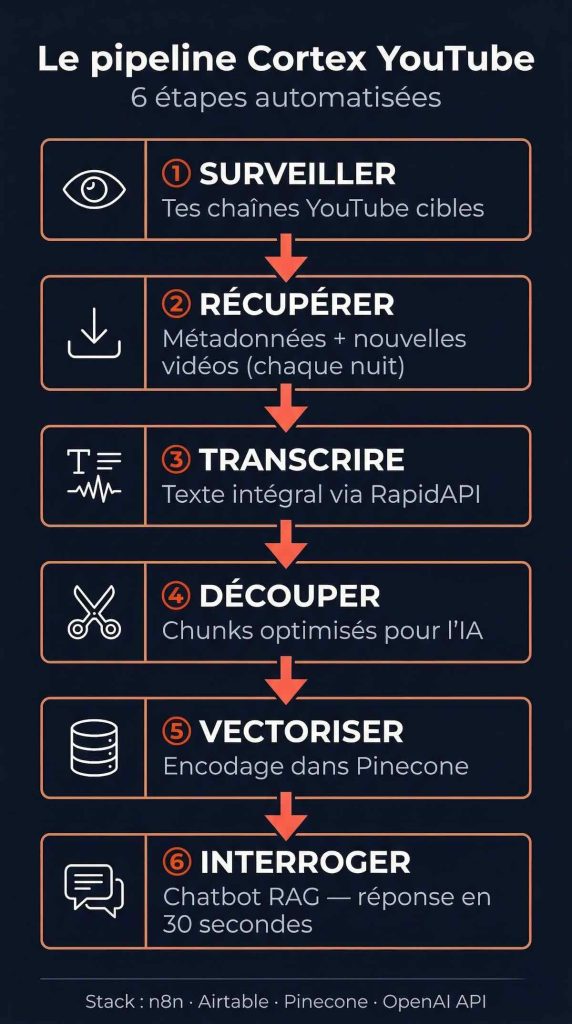
Étape 1 — Aspiration automatique des chaînes
Le workflow n8n surveille tes chaînes YouTube cibles chaque nuit et récupère automatiquement les nouvelles vidéos avec leurs métadonnées : titre, description, durée, date de publication, catégorie.
Tu ne sélectionnes pas les vidéos manuellement. Tu paramètres une fois les chaînes que tu veux suivre — avec l’identifiant technique de la chaîne, récupéré via RapidAPI (l’URL avec le @nom ne suffit pas pour les APIs). Ensuite, le système tourne sans toi.
Chaque matin, les vidéos de la veille sont déjà dans ta base Airtable. Triées, catégorisées, prêtes à traiter.
Point critique à comprendre : n8n ne lit pas un “statut” dans une cellule Airtable. Il lit une vue filtrée. C’est la vue qui définit ce que le workflow va traiter. Ça peut sembler un détail technique, mais c’est ce qui permet de déclencher ou de bloquer le traitement d’un lot de vidéos sans toucher au workflow lui-même.
Étape 2 — Transcription
La transcription se fait via RapidAPI (plan basique : 20 transcriptions gratuites par mois). Le workflow récupère le texte intégral de chaque vidéo et le stocke dans Airtable.
C’est toi qui décides quelles vidéos sont transcrites : tu les passes manuellement au statut “Waiting for Transcript” dans ta vue Airtable. Le workflow détecte, transcrit, met à jour le statut. Simple.
Le plan gratuit couvre 20 vidéos par mois. Au-delà, tu montes en puissance selon ton volume réel. Pas besoin de parier sur un volume hypothétique en amont.
Étape 3 — Vectorisation dans Pinecone
La vectorisation, c’est transformer le texte de chaque transcription en coordonnées numériques dans un espace mathématique. Pinecone stocke ces coordonnées. Quand tu poses une question, l’IA cherche les coordonnées les plus proches de ta question — et remonte les passages les plus pertinents.
Techniquement, le workflow découpe chaque transcription en blocs (chunks) optimisés, les encode via l’API OpenAI, puis les injecte dans Pinecone avec les métadonnées associées (chaîne, titre, catégorie).
Pinecone stocke 200+ vidéos gratuitement. Tu organises par catégorie : crypto, IA, e-commerce, cuisine — ce que tu veux. Un Cortex peut contenir plusieurs catégories isolées, ce qui te permet d’interroger soit toute ta base, soit un domaine précis.
Étape 4 — Le chatbot RAG
Le chatbot n8n se connecte directement à ton Pinecone. Il reçoit ta question, vectorise la requête, récupère les passages les plus pertinents, et génère une réponse basée uniquement sur ce qu’il a trouvé — avec les sources.
Le prompt système est la clé : “si la réponse n’est pas dans les extraits fournis, dis que tu ne sais pas.” Ça supprime les inventions. La réponse est sourcée ou elle n’existe pas.
Tu peux déployer ce chatbot en interne via n8n, sur un lien public, intégré sur un site web, ou connecté à Telegram ou WhatsApp. L’agent fonctionne comme point d’accès unique à toute ta base de connaissances.
👉 Voir la méthode complète Cortex YouTube : aspiration, transcription, Pinecone, chatbot RAG
Ce que ça coûte réellement de faire tourner le système
Le coût est ce qui convainc en dernier recours. Voici les chiffres réels, pas les estimations.
Airtable : gratuit jusqu’à 1 000 vidéos par base. Illimité en bases. Pour 99% des cas d’usage, tu n’as pas besoin de passer au payant.
Pinecone : gratuit pour 200+ vidéos stockées. Suffisant pour une base de veille solide.
RapidAPI : plan basique à 0€ pour les 20 premières transcriptions par mois. À calibrer selon ton volume.
OpenAI API : 2 à 5€ par mois pour un usage personnel standard.
n8n : c’est là que ça se joue. n8n Cloud coûte 24€/mois pour 2 500 exécutions de workflow. Si tu dépasses, tu es bloqué. L’alternative : héberger n8n sur un VPS à 6€/mois — exécutions illimitées, données chez toi, zéro contrainte de volume. C’est la solution que Cyril utilise et recommande.
Total : entre 8 et 11€/mois selon l’usage API. C’est le coût de fonctionnement d’un système qui tourne 24h/24 sans intervention.
Cyril a réduit son temps de synthèse et de rédaction post-vidéo de 3 à 4 heures à 2 minutes. Sa newsletter se génère depuis sa propre base de données. Objectif documenté : passer de 250 000€ à 500 000€ de CA en un an en automatisant les tâches à faible valeur ajoutée.
Ce que tu peux faire avec ta base une fois opérationnelle
La base de connaissances est le réservoir. Ce que tu en fais, c’est ouvert.
Génération de contenu : tu interroges ta base pour trouver des angles, des chiffres, des citations vérifiées. Tu ne pars plus d’une page blanche. Tu pars de données.
Support client : tu uploadles tes guides ou formations dans YouTube (même en privé), tu transcris, tu vectorises. Le chatbot répond aux questions de tes clients en 30 secondes depuis ton propre contenu.
Veille sectorielle : tu suis 5 à 15 chaînes. L’aspiration tourne à minuit. Le matin, tu interroges et tu as la synthèse — au lieu de regarder 2h de vidéos.
Chatbot thématique public : tu construis une base sur un sujet (crypto, IA, e-commerce, running), tu l’ouvres en accès public via un lien, et tu proposes un assistant spécialisé à ta communauté.
La logique est la même dans chaque cas : aspire → transcris → vectorise → interroge. Les sorties changent, la mécanique reste identique.
Questions fréquentes
Est-ce que je dois savoir coder pour construire ce système ?
Non. n8n est une plateforme d’automatisation no-code avec une interface visuelle. Tu connectes des modules entre eux, tu configures tes paramètres (credentials, catégories, chaînes cibles). Les workflows JSON sont fournis en fichiers importables en un clic : tu modifies uniquement tes paramètres personnels, tu n’écris rien de zéro.
Pinecone peut halluciner si le chatbot ne trouve pas de réponse dans la base ?
Avec un prompt système mal cadré, oui. Avec un prompt qui indique explicitement “si la réponse n’est pas dans les extraits fournis, dis que tu ne sais pas”, le chatbot répond seulement depuis ce qu’il a trouvé. Ce n’est pas infaillible — un modèle peut toujours mal interpréter un passage ambigu — mais ça réduit fortement les inventions et sourcé chaque réponse.
Qu’est-ce qui se passe si YouTube supprime une vidéo déjà dans ma base ?
Rien. La transcription est stockée dans Airtable. Les vecteurs sont stockés dans Pinecone. Tu possèdes les données. La vidéo source peut disparaître de YouTube, tu conserves l’intégralité du contenu chez toi.
Conclusion — Le système ou le seau percé
Tu as deux options. Continuer à consommer du contenu YouTube sans système : tout entre, rien ne reste. Ou construire un Cortex qui aspire, transcrit et mémorise à ta place — pour que tu passes ton temps à interroger, pas à chercher.
L’architecture est connue. Les outils sont accessibles. Les coûts sont entre 8 et 11€/mois. Il n’y a pas de magie là-dedans. Il y a de l’ingénierie.